Author: Cédric Bhihe, researcher at the Barcelona Supercomputing Center
In a previous post we briefly showed how objects detected in an image by means of a specially trained computer vision (CV) model (viz. a convolutional neural network) may be analyzed on the basis of the bounding boxes that circumscribe the detected objects. This however constitutes only a fraction of what happens in the Saint George on a Bike project processing pipeline after object detection has taken place. The bounding box analysis itself is extended to extract relational and attribute properties from the image’s objects. That step is essential for the subsequent automatic generation of image captions.


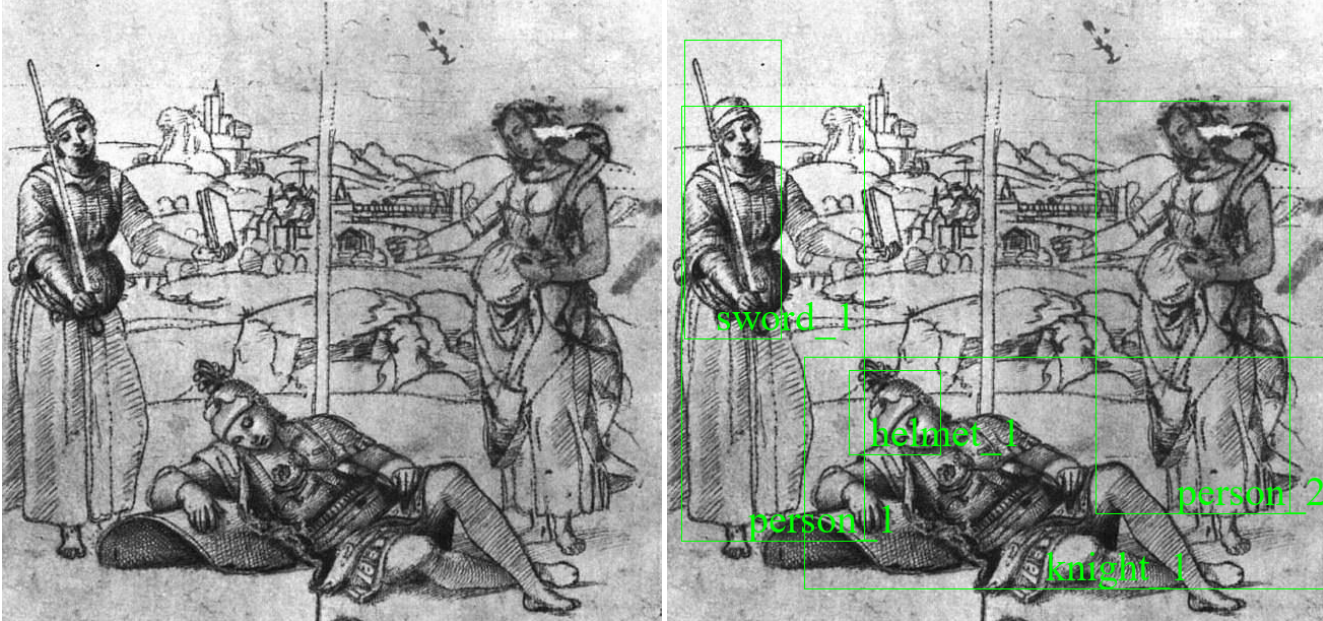
Figure 1 (left): Digitized image of “Jesus on the Cross” by Marco Pino, showing overlapping bounding boxes and their labels around objects detected by means of a trained computer vision model.
Figure 2 (right): Overlapping objects and caption seeds obtained on the basis of bounding box analysis by the Saint George on a Bike project. The caption seeds are either Triples or Attributes. They may require subsequent disambiguation (see red asterisks above) and give rise to elementary inferences (per the last section above).
Today’s post describes how exploring that path for a somewhat simple but realistic case yields interesting results. It also showcases a few of the remaining challenges. We show in particular how “caption seeds” or elementary captions are obtained and where disambiguation may be necessary, as the basis for a more complete description of the painting.
Our starting point is the canonical scene of Jesus Christ’s crucifixion by Master painter Marco Pino exhibited in Figure 1 along with detected objects and their bounding boxes. Detected objects are listed in the “Overlapping objects” section of Figure 2 above, with the exception of the object “skull_1” in Figure 1. Because “skull_1” does not overlap with any other bounding boxes, we opt to leave it out of this short presentation, for the sake of simplicity, and in spite of its symbolic importance (see yet another post for a previous discussion of that particular topic). Other objects selectively overlap pairwise as reflected by pairs listed in the first section of Fig. 2, e.g. “crucifixion_1 ++ crown_of_thorns_1”. An algorithmic analysis of the composition of the scene yields the result that, among all detected objects, “crucifixion_1” represents the main topic of the scene. It further informs us about overlap-clusters, which translate as relational properties of overlapping pairs of objects (denoted triples in Figure 2) or as properties of lone objects (denoted attributes in Figure 2).
Triples have the form (Subject, Verb, lexObject) as in (person_1, be_left::of, of;;crucifixion_1 [person]/[cross]) while attributes have the form (Subject, Verb, __), e.g. as in (person_2, stand, __) or (crucifixion_2 [person]/[cross], be_horizontal, __) where the lexical object denoted “lexObject” is missing. The wary reader will probably wonder at a few details and clamor for the following explanations:
- words are (mostly) lemmatized, meaning that their inflection disappears in favor of the basal form of the corresponding lexeme,
- in the triple (person_1, be_left::of, of;;crucifixion_1 [person]/[cross]), prepositions, such as “of”, are repeated as place holders to signify that the verb (Verb::of) relates to the lexical object formed as: “of;;lexObject”. This is useful when a specific verb grouping has more than one lexical object as for instance in the description: “The knight rides a horse on the river bank.” In this case our analysis would yield two triples involving the same verb’s lemma “ride” and two lexical objects where only the second is introduced the preposition “on”: (knight, ride::on, horse) and (knight, ride::on, on;;river_bank).
- in the triple (person_1, be_left::of, of;;crucifixion_1 [person]/[cross]), the lexical object “crucifixion_1” is followed by inferred entities in square brackets, both to enrich and adjust the semantics of the triple. The rule-based mechanism that triggers such enrichments based on detected object’s label lookup is automatic.
The remaining part of this post touches upon two important and algorithmically related subjects: disambiguation and basic inference in the produced caption seeds. Disambiguation may refer to several issues. Sometimes the processing algorithm will produce several instances of the same triple or attribute as exemplified in Figure 2 for the attribute identified by one red asterisk. In such a case deletion of superfluous elements is swift and easy. In other circumstances the processing algorithm may itself produce an ambiguous result, where (as in the case of the attribute identified by two red asterisks in Figure 2), the exact physical attitude of the praying figure of Saint Catherine of Siena is left undecided. This is due to the fact that (in this specific case) our object detection algorithm would require further fine-tuning to be able to recognize partial views of objects, instead of confusing such partial views with the representation of a squatting, crouching, … or otherwise of a “not standing” and “not lying” person.
Last but not least, it may be worth mentioning that even at the bounding box analysis stage, elementary inferences that pertain to levels one and two of Erwin Panofsky’s interpretation theory [1], can be made. In our case (crucifixion_1 [person], be_[jesus-christ],) proceeds from the fact that in a religious painting from the Italian Renaissance period, a person on a cross, coiffed with a crown of thorn is unequivocally a representation of Christ. The second algorithmic inference we present in Figure 2 is perhaps less straightforward in that it proceeds from the fact that the diminutive size and horizontal orientation of the detected object” “crucifixion_2” point to the fact that is is not a vertical cross supporting a full size crucified person, but rather a miniature representation of Christ on the Cross, that qualifies instead as a crucifix.
The so far untold reason for representing caption seeds in the form of (S,V,O) triples or (S,V,_) attributes is that such a condensed representation is the basis for describing complex scenes as knowledge graphs. This heralds a future in the making, when AI-powered automatic captioning of complex imagery will rely on graph-based inference, including a component of probability soft logic (loosely referred to as “fuzzy logic”), to identify scenes within an automatic Bayesian learning framework.
Saint George on a Bike: Training AI to be aware of cultural heritage contexts
Automatic image captioning is a process that allows already trained models running on commodity computers to generate textual descriptions from an image. It is a burgeoning reality in a handful of other areas such as classifying image contents on social media. However, to date, no AI system has been built and trained to help in the description of cultural heritage images, while factoring in the time-period and scene composition rules for sacred iconography from the 14th to the 18th centuries.
As part of the Saint George on a Bike project, researchers at Barcelona Supercomputing Center and Europeana build and train AI systems to help cultural heritage institutions describe and classify their art pieces automatically. In the end both casual users and cultural heritage professionals will benefit from a better access to collections (via index based search engines) and also a better experience navigating through collection catalogs. They will owe this to richer artwork annotations, leading to improved image scene indexation and search capabilities, obtained with the help of a specialized AI system.
To learn more about the Saint George on a Bike project, visit https://saintgeorgeonabike.eu/.
_______
[1] E. Panofsky, Meaning in the Visual Arts (1955), a collection of essays representing a select bibliography (180 items) published between 1914 and 1970, pp. 470, Garden City (NY), Doubleday Pub., in English.